
Kubernetesを学習していて、いくつか疑問が湧いてきました。
- ネットワークのセグメント跨いだワーカノードの構成は簡単にできるのか
- GPUを乗せた物理サーバをクラスタに追加して、ポッド上からGPUを使うことはできるのか
- 仮想サーバと物理サーバを混ぜた構成でクラスタが構築できるのか
これらの疑問を一気に解決するために、新しくKubeadmでクラスタを構築してみました!
結論
思ったより簡単にできます!
難しい内容で、皆様が逃げてしまわないように結論から書きました。
構築支援ツールのkubeadmを使えば比較的簡単に構築できます!
kubeadm偉大ですね。
今回の完成イメージ
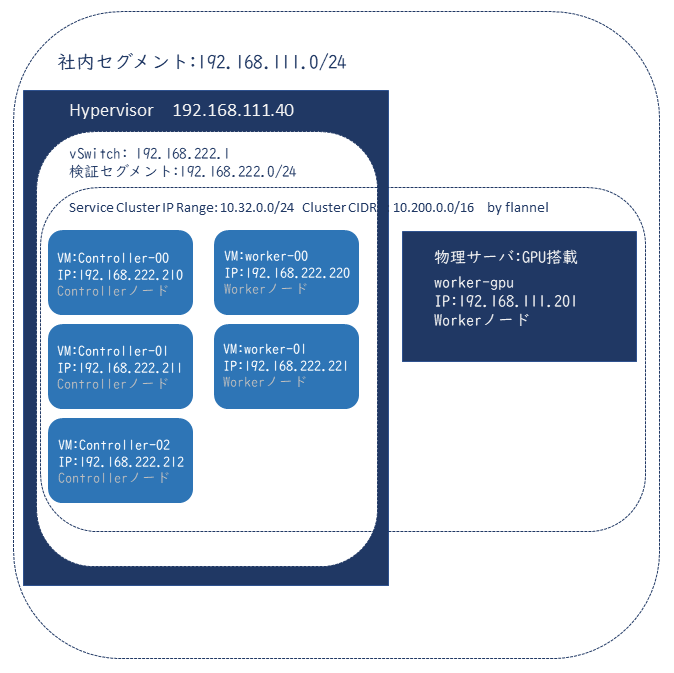
別セグメントにある、物理サーバを含めて、Kubernetesクラスタを構築します。
この環境では物理サーバと、その他のVMはルーティングされており、相互に通信ができます。
さて、この環境でKubernetesクラスタを構築していきましょう!
環境
| ホスト名 | cpu | メモリ | GPU | OS | 仮想/物理 |
|---|---|---|---|---|---|
| controller-00 | 2コア | 2GB | なし | Ubuntu18.04 | 仮想 |
| controller-01 | 2コア | 2GB | なし | Ubuntu18.04 | 仮想 |
| controller-02 | 2コア | 2GB | なし | Ubuntu18.04 | 仮想 |
| worker-00 | 1コア | 2GB | なし | Ubuntu18.04 | 仮想 |
| worker-01 | 1コア | 2GB | なし | Ubuntu18.04 | 仮想 |
| worker-gpu | 8コア x2 | 128GB | NVIDIA Geforce GTX1060 | Ubuntu18.04 | 物理 |
Kubernetesコンポーネントのバージョンは以下です。
| コンポーネント | バージョン |
|---|---|
| Kubernetes | v1.18.2 |
| Docker | 19.03.8 |
| flannel | v0.12.0-amd64 |
| nvidia-docker2 | 1.0.0-rc10 |
| NVIDIA driver | 440.82 |
| NVIDIA device-plugin for Kubernets | 1.0.0-beta6 |
作業の流れ
作業の流れは大まかに、以下のようになります。
- 構築の準備
- OS基本設定
- 必要なパッケージのインストール
- GPUノードの準備
- kubeadm init実行
- flannelの構成
- kubeadm join実行
- NVIDIA device plugin for Kubernetesの構成
- GPUコンテナ動作確認
1. 構築の準備
kubernetesクラスタを構成するVM、物理サーバにOSをインストールして、ネットワーク設定などを行います。
それぞれお互いに通信できることを確認してください。
この際の注意点としてはクラスタ同士の通信に利用するNICは、OSの認識している1枚目のNICを利用するようにしてください!
他のNICでも構築はできますが、flannelのマニフェストを書き換えなくてはならず、非常に面倒になります。
2. OS基本設定
この項は全てのノードで実行します。
まずカーネルパラメータを設定します。
# cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# sudo sysctl --systemkubeletを起動するためにswapを無効化しておきます。ノードの再起動が発生する場合は/etc/fstabのswap行をコメントアウトしましょう。
# swapoff -a
# swapon --show
# swapon –showコマンドを実行して何も表示されなければ、swapは無効になっています。
3. 必要なパッケージのインストール
ここではすべてのノードにkubeadm, kubectl, kubelet, Dockerをインストールします。
Dockerをインストールします。
まず前提パッケージをインストールします。
# apt-get update && apt-get install -y \
> apt-transport-https ca-certificates curl software-properties-common gnupg2Dockerリポジトリを追加します。
# curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -
# add-apt-repository "deb [arch=amd64] \
> https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"Dockerをインストールします。
# apt-get update && apt-get install -y \
> containerd.io=1.2.13-1 \
> docker-ce=5:19.03.8~3-0~ubuntu-$(lsb_release -cs) \
> docker-ce-cli=5:19.03.8~3-0~ubuntu-$(lsb_release -cs)Docker設定ファイルを作成します。
# cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOFDockerデーモン用のディレクトリを作成します。
# mkdir -p /etc/systemd/system/docker.service.dDockerデーモンを起動する設定を行います。
# systemctl start docker
# systemctl enable docker
Synchronizing state of docker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable docker
#kubeadm, kubelet, kubectl をインストールします。
前提パッケージをインストールします。
# apt-get update && sudo apt-get install -y apt-transport-https curlkubenetesリポジトリのGPGキーをインストールします。
# curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
OK
#リポジトリを作成します。
# cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
#kubeadm, kubelet, kubectl をインストールします。
# apt-get update && apt-get install -y kubelet kubeadm kubectl勝手にアップデートされてバージョン差異が発生しないように、バージョンを固定します。
apt-mark hold kubelet kubeadm kubectlこれでGPUノード以外はクラスタを構成する準備ができました!
4. GPUノードの準備
物理サーバのGPUをコンテナから利用するための準備をします。
以下の作業が必要です。
- NVIDIAドライバのインストール
- nvidia-docker2の導入
NVIDIAドライバのインストール
GPUノードに適切なGPUドライバを確認します。
# apt install ubuntu-drivers-common
~~~~~~
# ubuntu-drivers devices
== /sys/devices/pci0000:40/0000:40:02.0/0000:41:00.0 ==
modalias : pci:v000010DEd00001C03sv000010DEsd00001C03bc03sc00i00
vendor : NVIDIA Corporation
model : GP106 [GeForce GTX 1060 6GB]
manual_install: True
driver : nvidia-driver-435 - distro non-free
driver : nvidia-driver-390 - distro non-free
driver : nvidia-driver-440 - distro non-free recommended ←
driver : xserver-xorg-video-nouveau - distro free builtin
#nvidia-driver-440が最適であることが分かりました。
NVIDIA公式からダウンロードしてインストールする方法もありますが、パッケージ管理ツール以外でインストールしてしまうと、カーネルモジュールの更新によって動作しなくなることがあるので、アップデート時も依存関係を考慮してくれるaptでインストールします。
# apt install nvidia-driver-440GPUが認識されているか確認してみます。
# nvidia-smi
Fri May 15 14:40:29 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.82 Driver Version: 440.82 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 106... Off | 00000000:41:00.0 Off | N/A |
| 25% 33C P8 9W / 120W | 0MiB / 6070MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
#ちゃんと認識されています。
これでドライバをインストールすることができました。
nvidia-docker2のインストール
GPUを利用するためのランタイムをインスト―ルします。
# distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
# curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
OK
# curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
deb https://nvidia.github.io/libnvidia-container/ubuntu18.04/$(ARCH) /
deb https://nvidia.github.io/nvidia-container-runtime/ubuntu18.04/$(ARCH) /
deb https://nvidia.github.io/nvidia-docker/ubuntu18.04/$(ARCH) /
# apt-get update && sudo apt-get install -y nvidia-docker2
~~~~~~~~
#
Dockerが利用するランタイムを変更します。
# vi /etc/docker/daemon.json
## 内容
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
Dockerを再起動& enableにしておきます。
# systemctl restart docker && systemctl enable docker
Synchronizing state of docker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable docker
Dockerのランタイムがnvidiaに変更されていることを確認します。
# docker info | grep Runtime
Runtimes: nvidia runc
Default Runtime: nvidia
WARNING: No swap limit support
#これでGPUノードの準備もできました!
5. kubeadm initの実行
さあ、ではkubeadm initコマンドでクラスタを構築しましょう!
ここでは1台のcontrollerノードに作業を実施すればいいので、controller-00にて作業を行います。
# kubeadm init --control-plane-endpoint 192.168.222.210:6443 \
> --upload-certs --pod-network-cidr=10.200.0.0/16 \
> --apiserver-advertise-address=192.168.222.210
~~~~~~~~~~~~~~~~~~~~~~~
Your Kubernetes control-plane has initialized successfully!
~~~~~~~~~~~~~~~~~~~~~~~これでkubernetesクラスタが構成されました!
この時に出力される中に[kubeadm join ~~~]というコマンドが2つあります。
controller追加用と、workerノード追加用です。
後ほど利用するので、メモ帳などにコピーしておいてください。
kubectl を利用するための設定をします。
# mkdir $HOME/.kube
# cp -p /etc/kubernetes/admin.conf $HOME/.kube/configkubectlが利用できることを確認します。
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
controller-00 NotReady master 42s v1.18.2この時点ではポッドネットワークがまだないため、[NotReady]となっています。
6. flannelの構成
ポッドネットワークとして、OverlayNWを構成できるflannelを構成します。
引き続きcontroller-00で作業します。
まずマニフェストをダウンロードします。
# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlマニフェストを一部書き換えます。
## kube-flannel.yml
変更前~~~~~
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
~~~~~~~~
↓
変更後~~~~~
net-conf.json: |
{
"Network": "10.200.0.0/16",
"Backend": {
"Type": "vxlan"
}
}
~~~~~~~~マニフェストを適用します。
# kubectl apply -f kube-flannel.yml
podsecuritypolicy.policy/psp.flannel.unprivileged created
clusterrole.rbac.authorization.k8s.io/flannel created
clusterrolebinding.rbac.authorization.k8s.io/flannel created
serviceaccount/flannel created
configmap/kube-flannel-cfg created
daemonset.apps/kube-flannel-ds-amd64 created
daemonset.apps/kube-flannel-ds-arm64 created
daemonset.apps/kube-flannel-ds-arm created
daemonset.apps/kube-flannel-ds-ppc64le created
daemonset.apps/kube-flannel-ds-s390x created
#flannelが正常に動作していることを確認します。
# kubectl get po -n kube-system | grep flannel
kube-flannel-ds-amd64-46492 1/1 Running 0 40s
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
controller-00 Ready master 2m43s v1.18.2
#flannelがポッドとして起動し、ノードがReadyになりました!
これで他のノードを追加すれば完了です!
7.kubeadm join実行
kubeadm init 実行時に出力された[kubeadm join]コマンドを実行して、各ノードをクラスタに追加していきます。
controller-01, controller-02
# kubeadm join 192.168.222.210:6443 --token hz1yk9.wx2wsn8rfhz4243s \
> --discovery-token-ca-cert-hash sha256:6170c56742029031fb2845088b8dec4f73d7d9e90459dd9e07a1ffc8eb619f9e \
> --control-plane --certificate-key e070f20334fe7b3ec58c85ddb3f22f9a90116ff05e842334f94a5fc336e6e957
~~~~~~~~~~~~~~~~~~
This node has joined the cluster and a new control plane instance was created:
~~~~~~~~~~~~~~~~~~
#worker-00, worker-01, worker-gpu
kubeadm join 192.168.184.213:6443 --token hz1yk9.wx2wsn8rfhz4243s \
> --discovery-token-ca-cert-hash sha256:6170c56742029031fb2845088b8dec4f73d7d9e90459dd9e07a1ffc8eb619f9e
~~~~~~~~~~~~~~~~~~
This node has joined the cluster:
~~~~~~~~~~~~~~~~~~
#ノードが追加されているか確認しましょう!
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
controller-00 Ready master 4d2h v1.18.2
controller-01 Ready master 4d v1.18.2
controller-02 Ready master 4d v1.18.2
worker-00 Ready <none> 4d v1.18.2
worker-01 Ready <none> 4d v1.18.2
worker-gpu Ready <none> 4d v1.18.2
#全ノードがReadyになりましたね!
これで通常のクラスタは完成です!
8.NVIDIA device plugin for Kubernetesの構成
まだKubernetesクラスタからGPUをリソースとして認識することができていないので、それができるプラグインを導入します。
参加したGPUノードのリソースを見てみましょう。
# kubectl describe node worker-gpu
Name: worker-gpu
Roles: <none>
~~~~~
Addresses:
InternalIP: 192.168.207.201
Hostname: worker-gpu
Capacity:
cpu: 32
ephemeral-storage: 1951507452Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 131948100Ki
pods: 110
Allocatable:
cpu: 32
ephemeral-storage: 1798509264786
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 131845700Ki
pods: 110
~~~~~
PodCIDR: 10.200.5.0/24
PodCIDRs: 10.200.5.0/24
Non-terminated Pods: (2 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system kube-flannel-ds-amd64-v4zsx 100m (0%) 100m (0%) 50Mi (0%) 50Mi (0%) 45s
kube-system kube-proxy-vv9kh 0 (0%) 0 (0%) 0 (0%) 0 (0%) 45s
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 100m (0%) 100m (0%)
memory 50Mi (0%) 50Mi (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
~~~~~
#
まだGPUに関わる情報が見えません。
NVIDIA device-pluginを適用してみます。
# wget https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/1.0.0-beta6/nvidia-device-plugin.yml
# kubectl -f apply nvidia-device-plugin.yml
daemonset.apps/nvidia-device-plugin-daemonset created
# デーモンセットで各ノードにGPUを参照するポッドを配置しているようです。
もう一度GPUノードを見てみます。
# kubectl describe node worker-gpu
Name: worker-gpu
Roles: <none>
~~~~~~
Addresses:
InternalIP: 192.168.207.201
Hostname: worker-gpu
Capacity:
cpu: 32
ephemeral-storage: 1951507452Ki
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 131948100Ki
nvidia.com/gpu: 1
pods: 110
Allocatable:
cpu: 32
ephemeral-storage: 1798509264786
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 131845700Ki
nvidia.com/gpu: 1
pods: 110
~~~~~~~~
PodCIDR: 10.200.5.0/24
PodCIDRs: 10.200.5.0/24
Non-terminated Pods: (3 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system kube-flannel-ds-amd64-v4zsx 100m (0%) 100m (0%) 50Mi (0%) 50Mi (0%) 64m
kube-system kube-proxy-vv9kh 0 (0%) 0 (0%) 0 (0%) 0 (0%) 64m
kube-system nvidia-device-plugin-daemonset-6ztxk 0 (0%) 0 (0%) 0 (0%) 0 (0%) 63m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 100m (0%) 100m (0%)
memory 50Mi (0%) 50Mi (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
nvidia.com/gpu 0 0
~~~~~~
#項目 nvidia.com/gpu: が追加されました。
9.GPUコンテナの動作確認
ポッド上からGPUが利用できるか確認します。
以下のマニフェストを作成して
# tens-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: tens-pod
spec:
containers:
- name: tens-container
image: tensorflow/tensorflow:latest-gpu-py3
command: ["/bin/sleep"]
args: ["3600"]
resources:
limits:
nvidia.com/gpu: 1 ←これでGPUを要求しています。適用します。
# kubectl apply -f tens-pod.yml
pod/tens-pod created
# k describe po | grep -e Name -e Node
Name: tens-pod
Namespace: default
Node: worker-gpu/192.168.207.201
SecretName: default-token-8c9dw
Node-Selectors: <none>
# ちゃんとGPUノードで起動していますね!
ポッドに接続してGPUが見えているか確認してみましょう!
# kubectl exec -it tens-pod -- /bin/bash
________ _______________
___ __/__________________________________ ____/__ /________ __
__ / _ _ \_ __ \_ ___/ __ \_ ___/_ /_ __ /_ __ \_ | /| / /
_ / / __/ / / /(__ )/ /_/ / / _ __/ _ / / /_/ /_ |/ |/ /
/_/ \___//_/ /_//____/ \____//_/ /_/ /_/ \____/____/|__/
WARNING: You are running this container as root, which can cause new files in
mounted volumes to be created as the root user on your host machine.
To avoid this, run the container by specifying your user's userid:
$ docker run -u $(id -u):$(id -g) args...
# nvidia-smi
Thu May 14 16:51:10 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.82 Driver Version: 440.82 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 106... Off | 00000000:41:00.0 Off | N/A |
| 25% 34C P8 9W / 120W | 0MiB / 6070MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
#ちゃんとGPUが認識されていますね!
Tensorflowの簡単なものを実行して、GPUが動作しているか確認してみましょう。
# python
## 以下をコピペして実行
from tensorflow.python.client import device_lib
device_lib.list_local_devices()
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train),(x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test)
実行中にGPUの負荷を見てみます。
# nvidia-smi
Thu May 14 17:16:14 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.82 Driver Version: 440.82 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 106... Off | 00000000:41:00.0 Off | N/A |
| 25% 44C P2 25W / 120W | 5905MiB / 6070MiB | 9% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 13584 C python 5895MiB |
+-----------------------------------------------------------------------------+
#負荷と温度がほんのり上がっているのが分かります。
また、ProssesにPythonが表示されています。
これでGPUポッドが実行できるKubernetesクラスタが完成しました!
おわりに
最後までお付き合いいただきありがとうございました。
とても長い記事になってしまいました。
kubeadmは、便利な構築支援ツールですが、便利ゆえうまくいかなかった場合に解決に時間がかかりそうです。
例えば[kubeadm init], [kubeadm join]あたりでエラーが出ると、そこまでの設定含めて検証が必要なので、結構大変です。
もしつまづいたら、まずはエラーの内容を理解してAPIリファレンス(Overview of kubeadm)を参照してみてください。